One result of a genetic genealogy test is the amount of DNA shared with another tester expressed in either centimorgans (cM) or percent.
How does that amount of shared DNA translate into the relationship? Sadly it's not unique and the smaller the amount shared the broader the range of possible relationships it implies. The relationship can only be expressed as a probability.
Suppose based on the amount of shared DNA, say 200 cM, there's a probability the relationship could be second cousin. It's a conditional probability which statisticians write as P(A|B) where A is the second cousin relationship and B the 200 cM of shared DNA.
To help the interpretation Blaine Bettinger's Shared Centimorgan Project compiled statistics of the distribution of shared cM for a given relationship. Using the same terminology, it's expressed as the conditional probability P(B|A).
P(B|A) is not necessarily the same thing as P(A|B). If it were the probability that a black animal is a dog would equal the probability a dog is a black animal.
![]() Bayes Theorem tells us how P(A|B) and P(B|A) are related. P(A) and P(B) are the probabilities of observing A (the relationship) and B (the amount of shared DNA) independently of each other; known as marginal probabilities. Only if P(A) = P(B) will P(A|B) = P(B|A).
Bayes Theorem tells us how P(A|B) and P(B|A) are related. P(A) and P(B) are the probabilities of observing A (the relationship) and B (the amount of shared DNA) independently of each other; known as marginal probabilities. Only if P(A) = P(B) will P(A|B) = P(B|A).
How do you determine the marginal probabilities? You establish an unbiased domain which is the same for both P(A) and P(B). A community known to dogs that are black would not be unbiased.
The domain could be the world. How many second cousins do you have? Perhaps 100? With a world population of 7.7 billion the marginal probability P(A) = 100/7.7 billion = 1.3 x 10E-7. But with how many people in the world do you share 200 cM? As only a few tens of millions of people have taken a DNA test, and a large fraction of those are in the USA how do you know the worldwide figure? You don't.
You might choose a domain such as all people who have taken a DNA test or tested with a particular company. In theory, you might know how many of those match at 200 cM (within a narrow range) but how would you know how many second cousins tested?
You might choose the domain of all those who responded to the Shared cM Project call. Everyone who did so was able to confirm the shared cM for a particular relationship. For a second cousin, the average was 233 cM with a range of 46 to 515 cM. The project found 18 other relationships where 200 cM was within the range of shared cM values found.
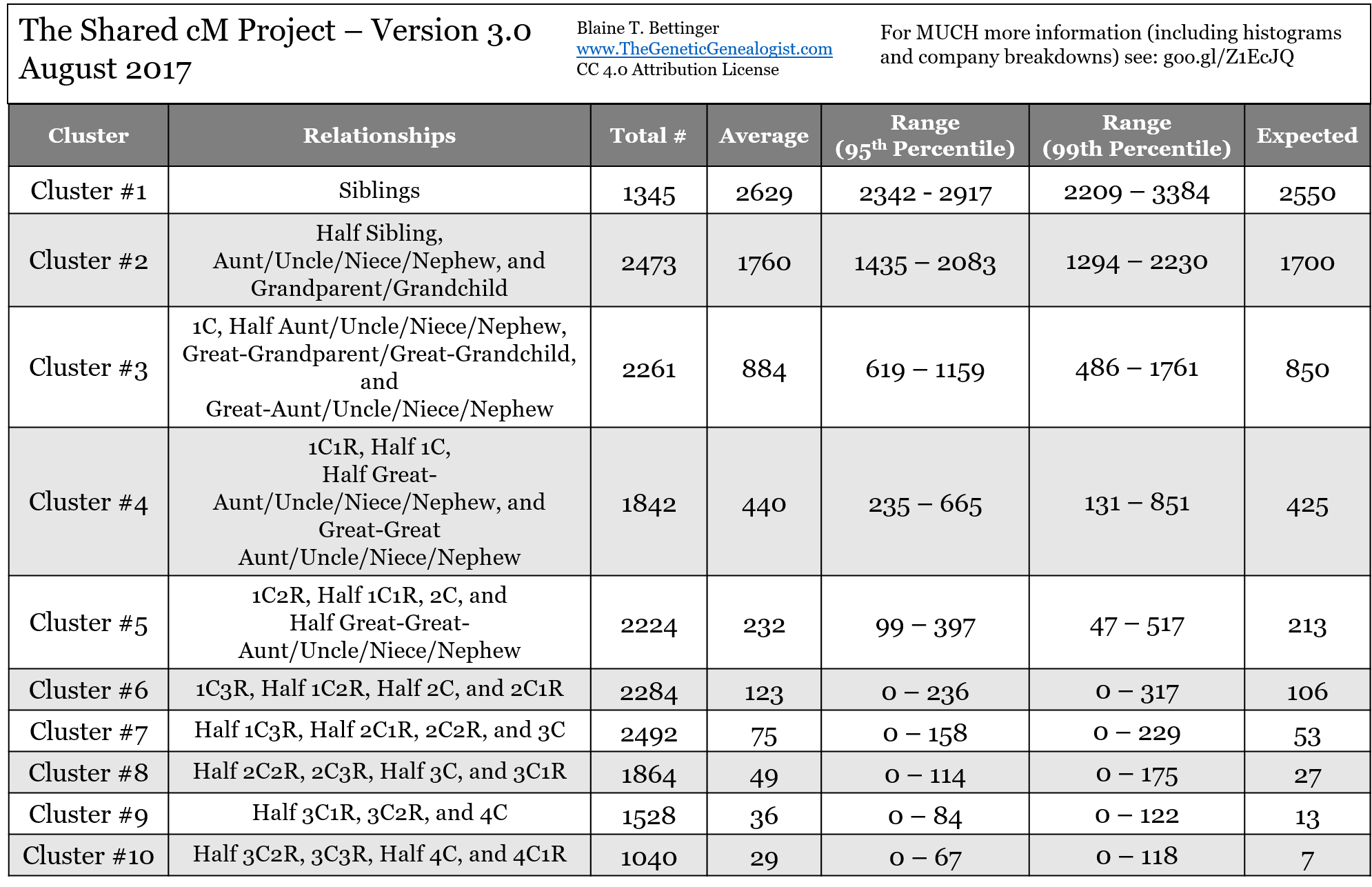
Another factor is endogamy. Specific results in Table 3 at https://thegeneticgenealogist.com/wp-content/uploads/2017/08/Shared_cM_Project_2017.pdf show that people from an endogamous population share more DNA than would be expected from the closest relationship as they are also more distantly related. The Shared cM survey shows that for a fourth cousin, where the expected shared DNA is 13 cM, those from non-endogamous populations share an average of 33 cM while endogamous populations share an average of 53 cM.
While looking further into this I noticed the ratio of the number of endogamous to non-endogamous cases reported changes systematically as the relationship becomes more distant. For 1st cousins, endogamous cases are 15% of the total, for 2nd cousins 12%, 3rd cousins 10% and 4th cousins 9%. Why would endogamy decrease for more distant relationships? Likely people don't know about endogamy for more distant relatives.
If you read this far — congratulations. The bottom line is the marginal probabilities P(A) and P(B) are not equal, although for larger amounts of shared DNA they may be close enough that the difference is insignificant. Moving to smaller amounts of shared DNA relationships are likely more distant than the assumption P(A|B) = P(B|A) often applied to the Shared cM Project sample implies.



4 comments:
John, I read this post right to the end feeling panic and sweats just like I did when I was a kid trying to solve word problems! LOL
John, I admire your ability to understand what you just blogged about. However, in my specific case, while the windows are open the shutters are closed. My brain shut down about half-way through about the 5th sentence. Cheers anyway, BT
Not everything in life is easy or learned quickly. Why anyone would feel obligated to share with a large audience the fact that they spent two minutes reading about a complex subject and decided it was beyond them is beyond me.
It's clear I need to have a cousin or three test on both sides [mat/pat] so I can use this chart in a logical manner with matches. Whew! A little science in the morning... Thanks so much John.
Post a Comment